

こんばんは〜
最近仕事でMeCabを導入する機会がありました。色々と詰まって悔しかったので、この機会にMeCabについて今までふわふわな理解しかしていなかった部分を徹底的に調べました。
これからMeCabを導入しようとしている人、インストール方法や辞書のカスタマイズ方法を調べている人、そもそもMeCabって何かわからない人、是非この記事を読んで今日からMeCabマスターになりましょう!
MeCabってなに?
早速MeCabについて見ていきましょう。まずはWikipedia先生の説明を引用してみます。
MeCabはオープンソースの形態素解析エンジンで、奈良先端科学技術大学院大学出身、現GoogleソフトウェアエンジニアでGoogle 日本語入力開発者の一人である工藤拓[1][2]によって開発されている。名称は開発者の好物「和布蕪(めかぶ)」から取られた。
開発開始当初はChaSenを基にし、ChaSenTNGという名前で開発されていたが、現在はChaSenとは独立にスクラッチから開発されている。ChaSenに比べて解析精度は同程度で、解析速度は平均3-4倍速い。
品詞情報を利用した解析・推定を行うことができる。MeCabで利用できる辞書はいくつかあるが、ChaSenと同様にIPA品詞体系で構築されたIPADICが一般的に用いられている。
https://ja.wikipedia.org/wiki/MeCab
はい。難しいですね・・・ここでのキーワードは形態素解析です。
MeCabとは、一言でいうと形態素解析を行ってくれるOSSです。
この前提をもとに次の説明に行ってみましょう。
形態素解析とは?
さて、形態素解析というキーワードが出てきましたが、これは一旦何なのでしょうか。この「形態素解析」を理解するとMeCabの使い方が理解できるようになります。
早速「形態素解析」について学んでいきましょう!
形態素解析を説明する前に、そもそも「形態素」って言葉を聞いたことがない方も多いと思われます。
形態素とは、「文章の中で、意味を持つ文字要素の最小単位」のことです。
ちょっと難しい表現になっちゃいましたね。この記事では「形態素 ≒ 単語」として説明します。厳密には違うのですが、まずは「形態素 ≒ 単語」という認識で読み進めて頂ければ大丈夫です!
具体的に、下記の文章を形態素(≒単語)で分解すると下記のような形になります。
犬も歩けば棒に当たる
↓ 形態素(≒単語)で分けるとこんな感じ
犬 / も / 歩け / ば / 棒 / に / 当たるこのように、文章の中の/で区切られた単語1つ1つを「形態素」と呼びます。
そして、ある文章を形態素に分解して、それぞれの形態素の品詞や活用を分析することを「形態素解析」と言います。
例えば下記の文章を形態素解析するとこのようになります。
犬も歩けば棒に当たる
↓形態素解析
書字形 語彙素 読み 品詞 活用型 活用形 発音形
犬 犬 イヌ 名詞-普通名詞-一般 イヌ
も も モ 助詞-係助詞 モ モ
歩け 歩く アルク 動詞-一般 五段-カ行 仮定形-一般 アルケ
ば ば バ 助詞-接続助詞 バ バ
棒 棒 ボウ 名詞-普通名詞-一般 ボー
に に ニ 助詞-格助詞 ニ ニ ニ
当たる 当たる アタル 動詞-一般 五段-ラ行 終止形-一般 アタル
こうやって、とある文章を形態素に分けることによって、それぞれの形態素に品詞を割り当てることが可能になり、文章をより精密に分析することができるようになります。
形態素解析は自然言語処理のはじめの一歩って訳なんですね〜
雑コラム:自然言語処理とは?
自然言語とは、人間が読み書きしたり、話したりする言葉のことです。まさに今あなたが読んでいるこの日本語も、実は自然言語の一部です。自然言語処理とは、この「人間が使う言葉」をプログラムで処理して色々やろうという試みのことです。
その活用例は多岐に渡りますが、代表的なものをいくつかピックアップして、本記事の最終章で紹介しますのでお楽しみに〜
単語と形態素の具体的な違いは下記記事が分かりやすく解説してくれているので、興味ある人はぜひ読んでみてください。興味深い内容になってます
まとめ:MeCabで出来ること
これまで形態素解析について説明してきましたが、MeCabとは、日本語の形態素解析を行うことに特化したソフトウェアです。前節の最後でも述べましたが、形態素解析は自然言語処理のはじめの一歩という訳で、MeCabで形態素解析を行った結果をもとに、何かの処理を行なって初めて効果を発揮することができます。形態素解析(自然言語処理)の活用事例については本記事の最終章で紹介します。この事例から、あなたの携わるシステムに活かせることはないか検討して頂けたら幸いです。
お待たせしました!それでは実際にMeCabをインストールする手順について、コマンドを交えて紹介していきます。
なお、本解説はCentOS Stream 9へのインストールを前提に解説していますのでご了承ください。
事前準備
まずはMeCab導入に必要なもの一式を下記コマンドでインストールして、mecabの作業用のディレクトリを作成しておきましょう。
sudo dnf install -y bzip2 bzip2-devel gcc gcc-c++ git make wget curl openssl-devel readline-devel zlib-devel patch file tar
mkdir ~/mecab_dir
cd ~/mecab_dirさて、これで準備は整ったので早速MeCab本体のインストールに移りましょう!
MeCab本体のインストール
# MeCabの圧縮ファイルをダウンロード
wget -O mecab-0.996.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE"
# 解凍
tar zxvf mecab-0.996.tar.gz
cd mecab-0.996
# コンパイルしてインストール
./configure --with-charset=utf8 --enable-utf8-only
make
sudo make install
mecab-config --libs-only-L | sudo tee /etc/ld.so.conf.d/mecab.conf
sudo ldconfig
# 作業ディレクトリに戻る
cd ~/mecab_dir/これでMeCab本体はインストールできたと思います!では続けて辞書のインストールに進みましょう!
雑コラム;MeCabの辞書とは?
MeCabの辞書とは、単語のデータベースのようなものです。
MeCabはこのデータベースに登録されている情報をもとに、文章から単語(形態素)を抜き出し、解析しています。
MeCabの標準辞書ipadicをインストール
# まずは辞書用のディレクトリを作って入る
mkdir ~/mecab_dir/mecab_ipdic
cd ~/mecab_dir/mecab_ipdic
# 辞書をダウンロード
wget 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM' -O mecab-ipadic-2.7.0-20070801.tar.gz
# 解凍
tar zxvf mecab-ipadic-2.7.0-20070801.tar.gz
# デフォルトでは標準辞書の文字コードがEUC-JPなので、UTF8に変換する
nkf --overwrite -Ew mecab-ipadic-2.7.0-20070801/*
cd mecab-ipadic-2.7.0-20070801
# 設定ファイルdicrc内の文字コード設定をUTF-8に変更
vi dicrc
--------- 下記部分を変更 ---------
... 前略
;config-charset = EUC-JP 先頭に;をつけてコメントアウト
config-charset = UTF-8 ;UTF-8に変更
... 後略
# インストール
sudo /usr/local/libexec/mecab/mecab-dict-index -f utf-8 -t utf-8
./configure --with-charset=utf8
make
sudo make installお疲れ様です!これでMeCabのインストールは完了です!mecabコマンドを打って形態素解析をやってみましょう!
mecabコマンドを打つと、入力待ちになります。好きな文章を入力してEnterを押してみましょう!形態素解析された内容が表示されるはずです!思う存分形態素解析を楽しんでください!辞める時は、「ctrl + c」でmecabから抜けられます。
mecab
インストール完了です!!
インストール 名詞,一般,*,*,*,*,インストール,インストール,インストール
完了 名詞,サ変接続,*,*,*,*,完了,カンリョウ,カンリョー
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
! 記号,一般,*,*,*,*,!,!,!
! 記号,一般,*,*,*,*,!,!,!
EOSさてさて、とりあえずMeCabはインストール出来ましたがデフォルトの辞書では少し心許ないです。。
そこで、デフォルトの辞書に加えて新語に強い辞書のNEologdと、自分自身のカスタム辞書を作成して、自分好みの形態素解析ソフトにカスタマイズしよう!
MeCab辞書のカスタマイズ方法
辞書のカスタマイズ方法は下記の2種類あります。
・システム辞書を変更する方法
・ユーザー辞書を作成する方法
システム辞書とは、NEologdやipadic等の、最初から用意されている辞書のことです。
対してユーザー辞書とは、ユーザーが独自に単語定義することができる辞書のことです。
どちらの方法でやるのが良いか、公式サイトには下記記載があります。
辞書更新が頻繁でないときや, 解析速度を落としたくない時は, 直接 システム辞書を変更するのがよいでしょう.
(中略)
システム辞書の更新は時間がかかります. 辞書の更新が頻繁な場合や, システム辞書を変更する権限が無い場合は, ユーザ辞書を作るのがいいでしょう.
https://taku910.github.io/mecab/dic.html
個人的には以下のような使い分けが良いんじゃないかなと考えています。
・環境構築時やメンテナンス期間中に実施する等で、サービスが稼働していない場合→ システム辞書の更新
・サービス稼働中のMeCabの辞書を更新する場合 → ユーザー辞書の作成・更新
どちらが良いかについては、あなたの状況に合わせて検討してみてください。
次節からはNEologdの導入を進めていきます。あとちょっとです!頑張りましょう!
辞書NEologdとは
NEologdとは何なのでしょうか?公式では、このように説明されています。
mecab-ipadic-NEologd は、多数のWeb上の言語資源から得た新語を追加することでカスタマイズした MeCab 用のシステム辞書です。
https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md
少し砕けた言い換えをすると、NEologdとは、新しく出来た造語や固有名詞がたくさん収録されたMeCab用の辞書です。
新語が登録されてることにより、文章の解析精度が向上する期待がある一方で、下記のようなデメリットも挙げられています。
https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md
- 固有表現の分類が不十分です
- 例えば一部の人名と製品名が同じ固有表現カテゴリに分類されています
- 固有表現では無い語も固有表現として登録されています
- 固有表現の表記とフリガナの対応づけを間違っている場合があります
- すべての固有表現とフリガナの組に対する人手による検査を実施していないためです
- 追加した副詞の品詞情報が全て’副詞,一般,,,,‘になっている
- 対応している文字コードは UTF-8 のみです
- インストール済みの MeCab が使用している ipadic が UTF-8 版である必要があります
MeCabの辞書をNEologdに変更することは良いことだけではないのですね。
この欠点を補うためにも、公式からは標準辞書との併用がオススメされています。
Web上の文書の解析をする際には、この辞書と標準のシステム辞書(ipadic)を併用することをオススメします。
https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md
NEologdのインストール
# 作業用ディレクトに入る
cd ~/mecab_dir/
# gitからmeologdをクローンしてくる
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
# 辞書のダウンロード実行
cd mecab-ipadic-neologd
./bin/install-mecab-ipadic-neologd -n -aこれでNEologd辞書をダウンロードすることが出来ました。
試しに「すもももももももものうち」という文章をMeCabで解析してみてください。標準辞書を使用している場合は、複数の形態素に分解されますが、NEologdを使用すると1つの単語として認識されるはずです。
これは「すもももももももものうち」という単語がNEologd辞書に登録されているためです。
# 標準辞書でMeCabを起動するコマンド
mecab
# 辞書を指定してMeCabを起動する際の書式
mecab -d /使用する辞書のフルパス
# neologdを使ってMeCabを起動する場合
mecab -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd
さて、これでNEologdを使用してMeCabを実行することが可能になりました。
次節では標準辞書にNEologdの辞書内容を追加して、標準辞書とNEologdを併用するための設定をしていきます。
MeCab標準辞書(ipadic)にNEologdの内容を追加する
ここからは標準辞書(ipadic)とNEologdを併用するために、標準辞書(ipadic)にNEologdの内容を追加します。
標準辞書に単語を追加する方法は下記手順で行います。
- ipadicディレクトリ内に、辞書を作成(コンパイル)するための元データ(CSVファイル)を格納する
- ipadicを作成(コンパイル)する
MeCabは単語情報を記載したCSVファイルを基に辞書を作成(コンパイル)します。
実際にどのような形式のCSVファイルがあるかみてみましょう
ls ~/mecab_dir/mecab_ipdic/mecab-ipadic-2.7.0-20070801 | grep csv
----- 出力結果 -----
Adj.csv
Adnominal.csv
Adverb.csv
Auxil.csv
(... 後略)いろんなCSVファイルがありますね。ここに新しいCSVファイルを追加もしくはCSVファイルの内容を修正して、辞書を再作成(コンパイル)することで、システム辞書の内容の変更が出来ます。
ちなみに、CSVファイルの中身は以下のようになっています。
やぼったい,19,19,6956,形容詞,自立,*,*,形容詞・アウオ段,基本形,やぼったい,ヤボッ>タイ,ヤボッタイ
やぼったし,23,23,6956,形容詞,自立,*,*,形容詞・アウオ段,文語基本形,やぼったい,ヤ>ボッタシ,ヤボッタシ
やぼったから,27,27,6956,形容詞,自立,*,*,形容詞・アウオ段,未然ヌ接続,やぼったい,>ヤボッタカラ,ヤボッタカラ
(... 後略)CSVにはこんな感じで単語が登録されているんですね。
CSVの形式については下記のとおりです。
システム辞書, ユーザ辞書, ともにエントリのフォーマットは同一です.
エントリは, 以下のような CSV で追加します. 名詞などの活用しない語だと, 登録は簡単です.
工藤,1223,1223,6058,名詞,固有名詞,人名,名,*,*,くどう,クドウ,クドウ左から,
表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音です.
左文脈IDは, その単語を左から見たときの内部状態IDです. 通常システム 辞書と同一場所にある left-id.def から該当する ID を選択します. 空にしておくと mecab-dict-index が自動的に ID を付与します.
右文脈IDは, その単語を右から見たときの内部状態IDです. 通常システム 辞書と同一場所にある right-id.def から該当する ID を選択します. 空にしておくと, mecab-dict-index が自動的に ID を付与します.
https://taku910.github.io/mecab/dic.html
ちなみに、コストとはMeCabが単語を判定するときに使用される重み付けの数値です。ここでは解説しませんが、MeCabの形態素解析のアルゴリズムと、コストについての詳しい解説は下記記事が詳細に説明してくれているので、興味がある方は読んでみてください。かなり深い内容になっているので、時間があれば読んでおいて損はないです。
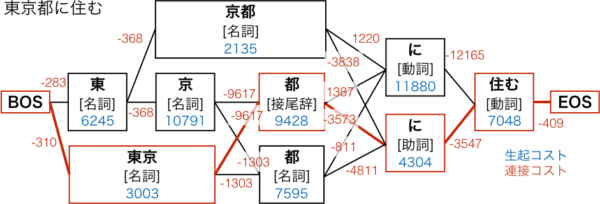
それでは実際にNEologdのCSVファイルをipadicディレクトリ内にコピーして、システム辞書の再作成を行いましょう。
NEologdではseedディレクトリの下に圧縮されたCSVファイルが保管されています。
作業手順は下記のとおりです。
- mecab-ipadic-neologd/seedディレクトリ配下の圧縮ファイルを解凍する
- ↑で解凍してできたCSVファイルたちを
mecab_ipdic/mecab-ipadic-2.7.0-20070801(ipadicのディレクトリ)配下にコピーする - システム辞書(ipadic)の再作成(コンパイル)実行
実際のコマンドは下記のとおりです。
# NEologd辞書の元データが格納されたディレクトリに移動
cd ~/mecab_dir/mecab-ipadic-neologd/seed
# データを解凍
unxz *.csv.xz
# CSVファイルたちをコピー
cp * ~/mecab_dir/mecab_ipdic/mecab-ipadic-2.7.0-20070801/
# ipadicのディレクトリに移動
cd ~/mecab_dir/mecab_ipdic/mecab-ipadic-2.7.0-20070801/
# NEologdのCSVファイルがコピーされているか確認
ls | grep neolog
# 辞書を再作成
/usr/local/libexec/mecab/mecab-dict-index -f utf8 -t utf8
sudo make installこれで標準辞書(ipadic)とNEologdが合体したシステム辞書が完成しました!
試しにmecabコマンドで「すもももももももものうち」を解析してみてください!一つの単語として認識されれば、問題なく完了です!
ユーザー辞書を作成して、MeCabにオリジナルの単語を認識させてみよう!
お疲れ様でした!ここまでの手順で標準辞書とNEologdが合体した辞書が作成されており、既にかなりの精度で解析ができるようになっていると思います。
しかし、特定の分野の単語や、自身の作った造語など、新たに辞書に登録したい場合も多々あると思います。
この節ではユーザー辞書を作成して、任意の単語をMeCabで検索できるようにする解説をします。
あともう一息!最後まで頑張りましょう!
まずは現状の形態素解析ではどうなるかを認識するために「阪神タイガース優勝」という文章をMeCabで解析してみましょう。
echo '阪神タイガース優勝' | mecab
阪神タイガース 名詞,固有名詞,組織,*,*,*,阪神タイガース,ハンシンタイガース,ハンシンタイガース
優勝 名詞,サ変接続,*,*,*,*,優勝,ユウショウ,ユーショーなんと!「阪神タイガース」と「優勝」という単語に分けられているではありませんか!!阪神タイガースと優勝を切り離すなんてけしからん!!「阪神タイガース優勝」は一つの単語だとMeCabに教えてやらねばなりません!!
ユーザー辞書を作成して、MeCabに認識させる手順は下記の通りです。
- CSVにコストを付与するための事前準備
- ユーザー辞書を保存するディレクトリを作成する
- ユーザー辞書作成のもととなるCSVファイルを作成する
- ↑で作成したCSVファイルにコストを追加する
- 3でコスト追加したCSVファイルからユーザー辞書を作成(コンパイル)
- 5で作成したユーザー辞書を参照するようにMeCabの設定変更
それでは実際のコマンドをどうぞ
# 事前準備
cd ~/mecab_dir
# コスト付与のためのモデルをDLしてくる
wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7bnc5aFZSTE9qNnM" -O mecab-ipadic-2.7.0-20070801.model.bz2
# モデルを解凍
bunzip2 mecab-ipadic-2.7.0-20070801.model.bz2
# モデルをUTF8形式に変換
nkf -w --overwrite ./mecab-ipadic-2.7.0-20070801.model
# モデルの設定もUTF8に変換
vi mecab-ipadic-2.7.0-20070801.model
----- 下記部分(6行目)をutf8に変更 -----
charset: utf-8
# 作業用のディレクトを作成(場所はどこでもいいです。ここでは既に作成している作業用ディレクトリ配下に作成します)
mkdir ~/mecab_dir/user_dic_dir
cd ~/mecab_dir/user_dic_dir/
# CSVファイルの作成(.csvで終わる名前であれば、なんでも良いです。)
vi hanshin.csv
----- 中身(最後にスペースや改行を入れるとエラーになります) -----
阪神タイガース優勝,,,10,名詞,一般,*,*,*,*,ハンシンタイガースユウショウ,ハンシンタイガースユウショウ,ハンシンタイガースユウショウ,ハンシンタイガースユーショー
# コスト値を自動で埋めるCSVファイルの生成
/usr/local/libexec/mecab/mecab-dict-index -m ~/mecab_dir/mecab-ipadic-2.7.0-20070801.model -d ~/mecab_dir/mecab_ipdic/mecab-ipadic-2.7.0-20070801/ -u hanshin_with_cost.csv -f utf8 -t utf8 -a hanshin.csv
# ユーザー辞書のコンパイル
/usr/local/libexec/mecab/mecab-dict-index -d /usr/local/lib/mecab/dic/ipadic -u user.dic -f utf8 -t utf8 hanshin_with_cost.csv
# 出来たユーザー辞書をMeCabが参照するように設定
vi /usr/local/etc/mecabrc
----- 下記内容を追加(ユーザー辞書は必ずフルパスで指定すること!) -----
userdic = /home/centos/mecab_dir/user_dic_dir/user.dicこれでユーザー辞書による単語の追加が完了しました!「阪神タイガース優勝」をmecabに解析させてみましょう!
echo '阪神タイガース優勝' | mecab
----- 以下出力内容 -----
阪神タイガース優勝 名詞,一般,*,*,*,*,ハンシンタイガースユウショウ,ハンシンタイガースユウショウ,ハンシンタイガースユウショウ,ハンシンタイガースユーショー
EOSやったね!今年も阪神優勝でお願いします!!
お疲れ様でした!
以上でMeCabの辞書カスタマイズ方法の解説は終了です!皆さんも自分の用途に合うように、カスタマイズして使用していきましょう!!
最後にMeCabを使った形態素解析が具体的にどんなところで使われているのか、活用事例をいくつか紹介して記事の締めとします。
活用事例その1:検索機能の最適化
まずは検索機能の最適化です。皆さんは検索するときにどういうふうに検索しますか?
単語を並べて検索?それとも文章で検索?
色々な検索方法がありますが、入力された文章を形態素に分解してから、検索をかけることで余計な文字を省いて、より精密な検索が出来るようになります。
例えば「阪神のピッチャー」という文章で検索された時、そのまま検索をかけるのではなく、形態素解析をして、「阪神」と「ピッチャー」という単語でアンド検索をかけるといった具合です。
後者の方がより良い検索結果が得られますよね。
また、形態素解析を使用した、高速に適切な検索が可能なインデックスの作成手法について、わかりやすく解説している記事があったので興味がある方は読んでみてください。
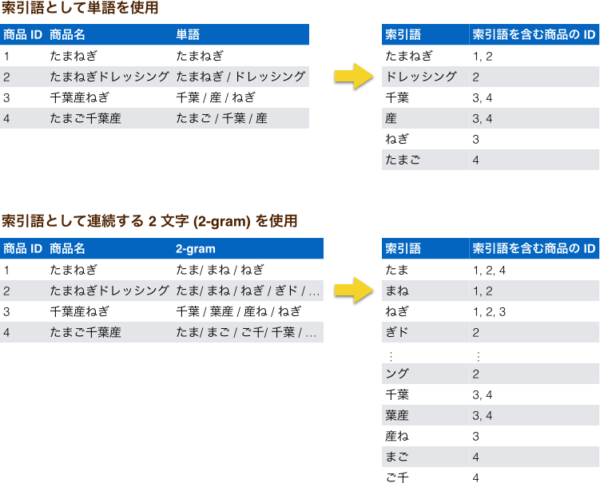
活用事例その2:自動応答チャットボット
最近様々なアプリやサイトで導入されている、チャットで質問すると関連するQ&Aページなどを返してくれるチャットボット。↓こういうウィジェットを見たことありませんか?
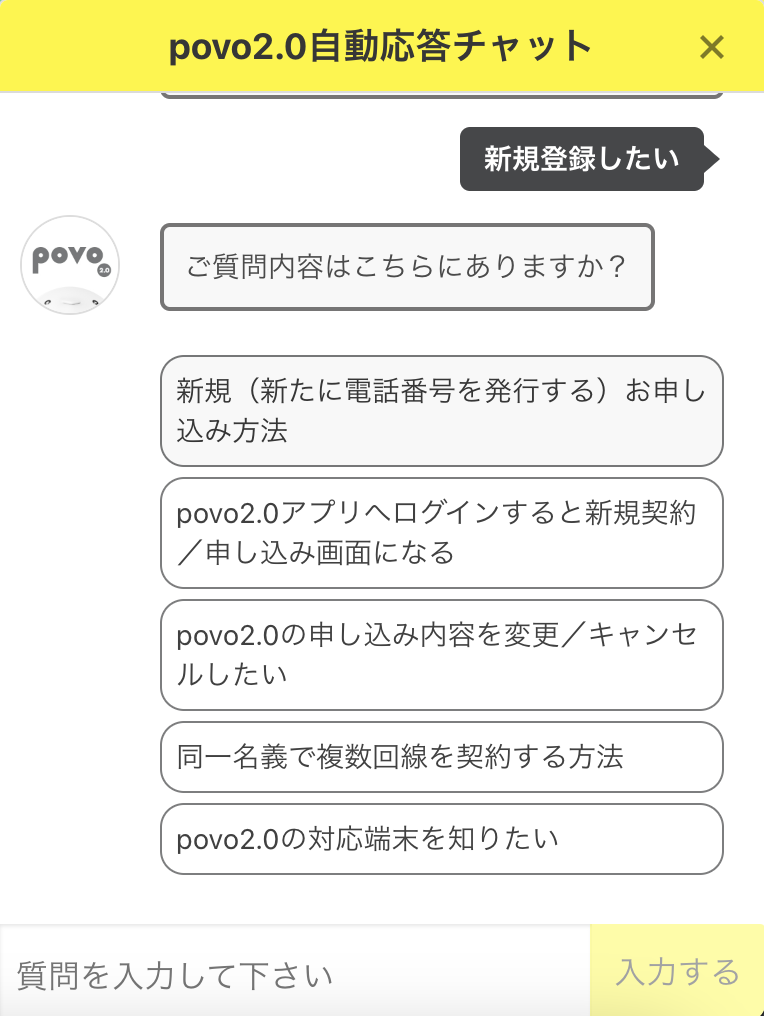
こういった自動応答チャットボットも、入力された文章から、形態素解析で必要な情報だけを抽出して、その情報を元に関連ページや回答を検索して返すことで実装が出来ます。
※例であげたpovoのチャットボットはより高度なアルゴリズムが使われているかもしれません。中の人ではないので知りませんが・・・
活用事例その3:Webスクレイピングの分析精度向上
現代ではWebスクレイピングで情報を収集することも多くなりました。ただ、正規表現や一般的なプログラムのみでその情報を正確に分析することは難しいです。
スクレイピングで集めたテキスト情報を、形態素解析を通してより精密に分析することが可能です。
下記記事はスクレイピングやAPIで集めた情報に形態素解析を通すことで、より精密に分析(この記事でやってることは名寄せ作業)を行う方法が解説されています。
こちらも面白い内容になっているので、ぜひご一読ください。

活用事例その4:テキストマイニング
テキストマイニングは様々な活用事例がありますが、テキストマイニングも形態素解析が根幹になっています。
以下箇条書きで代表的なテキストマイニング活用事例をあげます。
- お問い合わせデータから、単語の登場数を元に問題点を分析してサービス改善に役立てる
- SNS投稿から自社製品の感情分析を行い、商品改善に繋げる
- アンケートの自由入力欄から感情分析や頻出単語の抽出等の分析を行う
活用事例その5(予想):AIあんの
2024年の東京都知事選で活躍された安野たかひろさんが展開した「AIあんの」でも形態素解析が使用されていると思われます。「コメントから関連情報を検索する」部分や「寄せられたコメントの分析」の部分の処理で、形態素解析が行われていると思います。
AIあんのの裏側についての記事も公開されているので是非読んでみてください。これもかなり面白いです。

この記事ではMeCabの導入方法から、形態素解析とは何か?形態素解析の活用例まで紹介してきました。
MeCabは形態素解析を行うソフトであり、形態素解析は自然言語処理のはじめの一歩です。その活用方法はあなたのアイデア・発想次第で無限に広がっています。
MeCabを導入する手順を紹介するだけでなく、それを使ってどんなことをするか、この記事があなたの創造力をかき立てることが出来ていたら嬉しいです。
次のイノベーションはあなたから始まるかもしれません。
それではまたどこかでお会いしましょう〜!
現場からは以上です。

I really love your blog.. Very nice colors & theme. Did you crfeate
this amazing site yourself? Please reply back as I’m looking to create my own blog and want to find out where you
got this from or just what the theme is called. Thanks! https://Lvivforum.Pp.ua/